Tác giả: Iman Mirzadeh, Keivan Alizadeh, Hooman Shahrokhi, Oncel Tuzel, Samy Bengio, Mehrdad Farajtabar (Apple & Washington State University)
Tóm tắt
Trong những năm gần đây, các Mô hình Ngôn ngữ Lớn (LLMs) đã cho thấy khả năng ấn tượng trên nhiều lĩnh vực, bao gồm cả suy luận toán học. Benchmark GSM8K đã trở thành tiêu chuẩn phổ biến để đánh giá khả năng này. Tuy nhiên, câu hỏi đặt ra là: LIệu các số liệu đánh giá hiện tại có thực sự đáng tin cậy không, và khả năng suy luận của LLMs đã thực sự tiến bộ?
Nghiên cứu này giới thiệu GSM-Symbolic – một benchmark cải tiến được tạo từ các template biểu tượng, cho phép tạo ra nhiều câu hỏi đa dạng. Kết quả cho thấy LLMs có độ biến thiên đáng kể khi trả lời các phiên bản khác nhau của cùng một câu hỏi, và hiệu suất giảm đáng kể khi chỉ thay đổi các giá trị số. Đáng chú ý nhất, khi thêm một câu điều kiện có vẻ liên quan nhưng thực ra vô nghĩa, hiệu suất của tất cả các mô hình SOTA sụt giảm đến 65%.
1. Giới thiệu
1.1 Bối cảnh
LLMs đã chứng minh khả năng đáng kể trong nhiều lĩnh vực: xử lý ngôn ngữ tự nhiên, trả lời câu hỏi, sáng tạo và đặc biệt là suy luận toán học. Tuy nhiên, liệu các mô hình này có thực sự có khả năng suy luận logic vẫn là một câu hỏi mở.
Nhiều nghiên cứu cho thấy quá trình suy luận trong LLMs là khớp mẫu xác suất (probabilistic pattern-matching) chứ không phải suy luận chính thức (formal reasoning). Những thay đổi nhỏ trong đầu vào có thể làm thay đổi đáng kể đầu ra của mô hình, cho thấy sự nhạy cảm và tính mong manh của các mô hình này.
1.2 Hạn chế của GSM8K
Dataset GSM8K (Grade School Math 8K) bao gồm hơn 8000 câu hỏi toán học tiểu học và đã trở thành benchmark phổ biến để đánh giá khả năng suy luận toán học của LLMs. Tuy nhiên, GSM8K có những hạn chế nghiêm trọng:
- Chỉ cung cấp một số liệu đơn lẻ trên một tập câu hỏi cố định, không cho cái nhìn toàn diện
- Rủi ro nhiễm dữ liệu (data contamination) do tính phổ biến
- Tính chất tĩnh không cho phép các thí nghiệm có kiểm soát để hiểu rõ giới hạn của mô hình
1.3 Giải pháp: GSM-Symbolic
Để vượt qua những hạn chế trên, nhóm nghiên cứu tạo ra GSM-Symbolic – một benchmark sử dụng symbolic templates để tạo ra nhiều biến thể của câu hỏi, cho phép kiểm soát mức độ khó và đánh giá đáng tin cậy hơn.

Hình minh họa: Phân phối hiệu suất của các mô hình trên 50 tập dữ liệu được tạo từ GSM-Symbolic templates, cho thấy sự biến thiên đáng kể.
2. Nền tảng: Suy luận & Mô hình Ngôn ngữ
2.1 Định nghĩa suy luận logic
Nghiên cứu định nghĩa suy luận logic là quá trình mà một tác nhân sử dụng các bước logic để đạt được mục tiêu “mới”. Việc nhấn mạnh vào “tính mới” rất quan trọng vì nó giúp phân biệt suy luận thật sự với việc ghi nhớ giải pháp hoặc bắt chước các bước logic đã gặp trước đó.
2.2 Giả thuyết về khớp mẫu (Pattern-Matching Hypothesis)
Có một lượng lớn nghiên cứu cho thấy quá trình suy luận trong LLMs mong manh và không chính thức. Thay vì thực hiện suy luận formal, LLMs có thể thực hiện một dạng khớp mẫu xác suất và tìm kiếm dữ liệu gần nhất đã thấy trong quá trình huấn luyện, mà không thực sự hiểu các khái niệm:
- Jiang et al. (2024) cho thấy hầu hết LLMs vẫn gặp khó khăn với suy luận logic do token bias mạnh – đầu ra suy luận thay đổi khi một token đầu vào thay đổi
- Schaeffer et al. (2023) cho thấy xác suất trả lời đúng giảm theo cấp số nhân theo số lượng token cần phát ra đúng
- Dziri et al. (2023) biểu diễn bài toán suy luận dưới dạng đồ thị tính toán và phát hiện các đồ thị con tính toán đầy đủ xuất hiện thường xuyên hơn trong dữ liệu huấn luyện cho dự đoán đúng
- Razeghi et al. (2022) cho thấy mối tương quan giữa tần suất trong dữ liệu huấn luyện và hiệu suất kiểm tra
3. GSM-Symbolic: Thiết kế và Phương pháp
3.1 Quy trình tạo Template
Quá trình tạo template biểu tượng được minh họa trong Hình 1 của bài báo:
Bước 1: Từ một câu hỏi cụ thể trong tập test GSM8K, nhóm nghiên cứu tạo ra các template có thể phân tích được.
Bước 2: Quá trình annotation bao gồm việc xác định:
- Các biến số (variables)
- Miền giá trị (domains) của chúng
- Các điều kiện cần thiết để đảm bảo tính đúng đắn của cả câu hỏi và câu trả lời
Ví dụ, trong template:
When {name} watches her {family}, she gets out a variety of toys...
- name = sample(names)
- family = sample(["nephew", "cousin", "brother"])
- x = range(5, 100)
- y = range(5, 100)
- z = range(5, 100)
- total = range(100, 500)
- ans = range(85, 200)
# Điều kiện: x + y + z + ans == total
Bước 3: Kiểm tra tự động bao gồm:
- Xác minh không có giá trị biến gốc xuất hiện trong template
- Kiểm tra giá trị gốc thỏa mãn tất cả điều kiện
- Xác nhận câu trả lời cuối cùng khớp với câu trả lời câu hỏi gốc
- 10 mẫu ngẫu nhiên mỗi template được xem xét thủ công
- Xác minh ít nhất 2 mô hình trả lời đúng mỗi câu hỏi
3.2 Thiết lập thí nghiệm
Mô hình được đánh giá:
- Hơn 20 mô hình mở có kích thước từ 2B đến 27B tham số
- Các mô hình đóng: GPT-4o-mini, GPT-4o, o1-mini, o1-preview
- Tổng cộng gần 500 lần đánh giá trên nhiều thiết lập
Cài đặt đánh giá:
- Sử dụng 100 template, sinh 50 mẫu mỗi template = 5000 ví dụ
- 50 bộ dữ liệu, mỗi bộ gồm 100 ví dụ
- Sử dụng Chain-of-Thought (CoT) prompting với 8-shots và greedy decoding
- Format prompt bao gồm system instruction, 8 câu hỏi mẫu và câu hỏi mục tiêu
4. Thí nghiệm và Kết quả
4.1 Kết quả GSM8K hiện tại có đáng tin cậy không?
Đây là thí nghiệm đầu tiên và quan trọng nhất. Các mô hình SOTA được đánh giá trên GSM-Symbolic.

Kết quả chính:
- Tất cả mô hình đều thể hiện phương sai không đáng bỏ qua trên 50 tập dữ liệu khác nhau:
- Gemma2-9B: khoảng cách giữa hiệu suất tệ nhất và tốt nhất hơn 12%
- Phi-3.5-mini: khoảng cách khoảng 15%
-
Hiệu suất trên GSM8K gốc thường nằm ở phía bên phải của phân phối GSM-Symbolic (đúng cho 21/25 mô hình), nghĩa là hiệu suất GSM8K thường cao hơn đáng kể so với trung bình trên GSM-Symbolic
-
Điều này gợi ý khả năng nhiễm dữ liệu (data contamination) – một số ví dụ test GSM8K vô tình xuất hiện trong tập huấn luyện của các mô hình

Hình trên cho thấy hiệu suất giảm đáng kể từ GSM8K sang GSM-Symbolic đối với nhiều mô hình, đặc biệt là:
- Gemma2-9B, Phi-3, Phi-3.5, Mathstral-7B: giảm đáng kể
- Llama3-8b, GPT-4o: giảm không đáng kể (GSM8K gần tâm phân phối)
4.2 Khả năng suy luận toán học trong LLMs mong manh như thế nào?
Nghiên cứu tiếp tục điều tra tác động của loại thay đổi đến hiệu suất, so sánh giữa việc thay đổi tên riêng (person names, foods, currencies…) và thay đổi số.

Phát hiện quan trọng:
| Loại thay đổi | Mức độ ảnh hưởng | So sánh với GSM8K gốc |
|—|—|—|
| Chỉ thay đổi tên riêng | Phương sai thấp hơn | GSM8K gần tâm phân phối hơn |
| Chỉ thay đổi số | Phương sai cao hơn | GSM8K lệch nhiều khỏi tâm |
| Thay đổi cả tên và số | Phương sai cao nhất | GSM8K lệch xa nhất |
Xu hướng rõ ràng: Khi tăng từ chỉ thay tên → chỉ thay số → thay cả hai, phân phối hiệu suất dịch chuyển dần sang trái (giảm准确 độ) và phương sai tăng.
Điều đáng lo ngại: Ngay cả khi chỉ thay đổi tên riêng, hiệu suất vẫn có sự biến thiên đáng kể – điều mà một học sinh tiểu học có hiểu toán học thực sự sẽ không bao giờ gặp.
4.3 Mức độ khó ảnh hưởng thế nào đến phân phối hiệu suất?
Nghiên cứu tạo ra các biến thể với mức độ khó khác nhau bằng cách thêm hoặc bớt các điều kiện (clauses):
- GSM-M1 (Minus-1): Giảm 1 clause (dễ hơn)
- GSM-Symbolic: Giữ nguyên
- GSM-P1 (Plus-1): Thêm 1 clause (khó hơn)
- GSM-P2 (Plus-2): Thêm 2 clauses (khó nhất)

Kết quả nhất quán trên tất cả mô hình:
Khi độ khó tăng từ GSM-M1 → GSM-Symbolic → GSM-P1 → GSM-P2:
- Trung bình hiệu suất giảm – phân phối dịch chuyển sang trái
- Phương sai tăng – sự không ổn định lớn hơn
- Tốc độ giảm phản ánh có xu hướng nhanh hơn số bước suy luận cần thiết, phù hợp với giả thuyết khớp mẫu
4.4 LLMs có thực sự hiểu các khái niệm toán học?
Đây là phần thí nghiệm揭示 nhất. Nhóm nghiên cứu giới thiệu GSM-NoOp – một dataset thiết kế đặc biệt.
Ý tưởng: Thêm vào câu hỏi những thông tin có vẻ liên quan nhưng thực ra hoàn toàn không ảnh hưởng đến quá trình tính toán cần thiết để giải bài toán. Vì những thông tin này không có tác động, nên được gọi là “No-Op” (No Operation).
Ví dụ kinh điển:
“Oliver picks 44 kiwis on Friday. Then he picks 58 kiwis on Saturday. On Sunday, he picks double the number of kiwis he did on Friday, but five of them were a bit smaller than average. How many kiwis does Oliver have?”
Câu trả lời đúng chỉ cần: 44 + 58 + (2 × 44) = 190 kiwis. Việc “5 quả nhỏ hơn trung bình” hoàn toàn không liên quan.
Tuy nhiên, cả o1-mini lẫn Llama3-8B đều trả lời sai bằng cách trừ 5:
- 88 – 5 = 83 (sunday)
- 44 + 58 + 83 = 185 (SAI)

Kết quả bất ngờ:
| Mô hình | GSM8K (Full) | GSM-Symbolic | GSM-M1 | GSM-P1 | GSM-P2 | GSM-NoOp |
|---|---|---|---|---|---|---|
| Gemma2-9b | 85.3 | 79.1 (±2.99) | 71.2 (±2.81) | 44.0 (±5.69) | 41.8 (±6.00) | 22.3 (±5.11) |
| Phi-3-mini | 83.7 | 80.7 (±2.94) | 85.9 (±2.44) | 63.4 (±5.63) | 37.5 (±5.76) | 18.0 (±3.83) |
| Phi-3.5-mini | 84.9 | 82.1 (±3.38) | 87.6 (±1.98) | 64.8 (±5.43) | 44.8 (±6.32) | 22.4 (±4.03) |
| Mathstral-7b | 80.1 | 74.0 (±3.49) | 82.9 (±2.87) | 57.4 (±5.20) | 35.5 (±5.07) | 20.4 (±3.58) |
| Llama3-8b | 55.8 | 74.6 (±2.94) | 79.5 (±3.62) | 53.8 (±4.54) | 12.3 (±3.43) | 18.6 (±3.86) |
| GPT-4o-mini | 94.2 | 91.7 (±2.02) | 92.5 (±1.63) | 81.1 (±3.05) | 72.4 (±4.57) | 54.1 (±3.85) |
| GPT-4o | 95.2 | 94.9 (±1.87) | 94.4 (±1.62) | 93.9 (±2.59) | 88.0 (±3.43) | 63.1 (±4.53) |
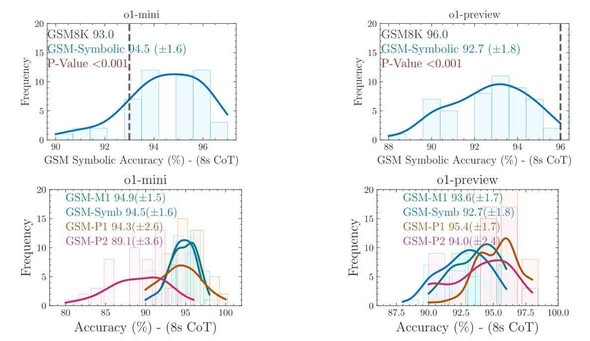
| o1-mini | 95.1 | 94.5 (±1.58) | 94.9 (±1.49) | 94.3 (±2.57) | 89.1 (±3.56) | 66.0 (±4.60) |
| o1-preview | 94.9 | 92.7 (±1.82) | 93.6 (±1.68) | 95.4 (±1.72) | 94.0 (±2.38) | 77.4 (±3.84) |
Sự sụt giảm thảm khốc trên GSM-NoOp:
- Phi-3-mini: từ 83.7% → 18.0% (giảm ~65%)
- GPT-4o: từ 95.2% → 63.1%
- o1-preview: từ 94.9% → 77.4%
- o1-mini: từ 95.1% → 66.0%
- Thậm chí các mô hình tốt nhất cũng sụt giảm nghiêm trọng
4.5 Few-Shot và Fine-Tuning không giải quyết được vấn đề
Nghiên cứu cũng kiểm tra xem việc cung cấp thêm ví dụ (in-context shots) hoặc fine-tuning có khắc phục được vấn đề NoOp không:
Thí nghiệm 1 – NoOp-Symb: Cung cấp 8 shots từ GSM-Symbolic của cùng câu hỏi trong context
- Kết quả: Hiệu suất vẫn nằm trong độ lệch chuẩn, không cải thiện đáng kể
- Ngay cả khi 8 ví dụ mẫu cung cấp đầy đủ chuỗi suy luận cần thiết, mô hình vẫn không thể nhận ra thông tin thêm là không liên quan
Thí nghiệm 2 – NoOp-NoOp: Cung cấp 8 shots từ các câu hỏi khác trong GSM-NoOp
- Kết quả: Llama3-8B giữ nguyên hiệu suất, Phi-3 hơi giảm
- Điều này cho thấy vấn đề sâu hơn và không thể giải quyết bằng few-shot prompting
Thí nghiệm 3 – Fine-tuning trên GSM-P1: Fine-tune Phi-3.5 trên GSM-P1
- Kết quả: Cải thiện nhẹ trên GSM-P1 nhưng giảm hiệu suất trên GSM-P2
- Scaling training data không giúp cải thiện khả năng suy luận
5. Kết quả bổ sung
5.1 Ablation: Tính chính xác số học
Một câu hỏi quan trọng: Liệu sự giảm hiệu suất có phải do lỗi tính toán không?

Nhóm nghiên cứu cho thấy:
- Các model hiện đại như Gemma2-9B đạt độ chính xác gần 100% trên phép cộng/trừ đến 4 chữ số
- Phân phối số chữ số trong GSM-Symbolic tương tự GSM8K gốc → không có sự khác biệt đáng kể về độ khó arithmetic
- Lỗi arithmetic không thể giải thích sự sụt giảm hiệu suất lớn trên GSM-P2 hay GSM-NoOp
| Benchmark | 1-digit | 2-digits | 3-digits | 4-digits | 5-digits | All |
|---|---|---|---|---|---|---|
| GSM8K | 99.8 | 99.1 | 99.3 | 96.8 | 95.9 | 98.9 |
| GSM-Symbolic | 99.7 | 99.2 | 97.6 | 97.2 | 99.1 | 98.3 |
| GSM-P1 | 97.5 | 98.6 | 98.7 | 96.2 | 99.5 | 97.4 |
| GSM-P2 | 96.2 | 98.6 | 97.5 | 96.4 | 99.2 | 97.1 |
5.2 Kết quả trên o1-preview và o1-mini
Các mô hình o1 của OpenAI cho kết quả mạnh hơn đáng kể so với các mô hình mở. Tuy nhiên:
- o1-mini vẫn tuân theo pattern tương tự: hiệu suất giảm khi độ khó tăng
- o1-preview cho kết quả ổn định hơn trên tất cả mức độ khó
- Cả hai vẫn sụt giảm nghiêm trọng trên GSM-NoOp
- o1-preview hiển thị “lạm dụng” thông tin inflation dù câu hỏi đã nói rõ giá là “bây giờ”
- o1-mini và o1-preview đều trừ số lượng “được quyên góp” dù không cần thiết
6. Kết luận
Những phát hiện cốt lõi
-
Kết quả GSM8K hiện tại không hoàn toàn đáng tin cậy – hiệu suất trên câu hỏi gốc thường cao bất thường so với phân phối GSM-Symbolic, gợi ý nguy cơ nhiễm dữ liệu
-
Suy luận toán học trong LLMs rất mong manh:
- Chỉ thay đổi tên riêng → vẫn có sự biến thiện
- Thay đổi số → biến thiên và giảm đáng kể hơn
- Càng khó → càng sai nhiều và không ổn định
- LLMs không thực sự hiểu khái niệm toán học:
- Thêm thông tin “có vẻ liên quan nhưng vô nghĩa” → sụt giảm đến 65%
- Mô hình có xu hướng mù quáng chuyển đổi câu văn thành phép toán mà không hiểu ý nghĩa
- Few-shot và fine-tuning không khắc phục được
- Hành vi của LLMs phù hợp với giả thuyết khớp mẫu (pattern-matching) – tìm kiếm và sao chép các bước suy luận đã gặp trong dữ liệu huấn luyện, thay vì thực hiện suy luận formal
Tầm nhìn tương lai
Nghiên cứu nhấn mạnh sự cần thiết:
- Phát triển phương pháp đánh giá đáng tin cậy hơn không phụ thuộc vào số liệu đơn lẻ
- Nghiên cứu sâu hơn về khả năng suy luận thực sự của LLMs
- Phát triển hệ thống AI có khả năng suy luận formal, vượt ra ngoài probabilistic pattern matching untuk đạt được khả năng giải quyết vấn đề ổn định và tổng quát hơn
“Ultimately, our work underscores significant limitations in LLMs’ ability to perform genuine mathematical reasoning. Their reasoning is fragile and may be more akin to sophisticated pattern matching rather than true logical reasoning.”
Source link: GSM-Symbolic: Understanding the Limitations of Mathematical Reasoning in Large Language Models