# HunyuanVideo – Mô Hình Tạo Video AI Mã Nguồn Mở Lớn Nhất Từ Tencent Với 13 Tỷ Tham Số
—
## Giới thiệu chung
**HunyuanVideo** là một mô hình nền tảng tạo video mã nguồn mở do **Tencent-Hunyuan** phát triển, được công bố kèm theo paper trên arXiv (arXiv:2412.03603). Với hơn **13 tỷ tham số**, đây được xem là mô hình tạo video open-source lớn nhất tính đến thời điểm phát hành. Repo chứa các định nghĩa mô hình PyTorch, trọng số đã huấn luyện trước và mã suy luận.
![]()
—
## Các chức năng chính từ nguồn
### 1. Text-to-Video Generation – Tạo video từ văn bản
Đây là chức năng cốt lõi của HunyuanVideo. Người dùng nhập một đoạn mô tả văn bản (prompt), mô hình sẽ tạo ra video tương ứng. Các thông số được hỗ trợ:
| Độ phân giải | Tỷ lệ 9:16 | Tỷ lệ 16:9 | Tỷ lệ 4:3 | Tỷ lệ 3:4 | Tỷ lệ 1:1 |
|—|—|—|—|—|—|
| **540p** | 544×960×129f | 960×544×129f | 624×832×129f | 832×624×129f | 720×720×129f |
| **720p (khuyến nghị)** | 720×1280×129f | 1280×720×129f | 1104×832×129f | 832×1104×129f | 960×960×129f |
Chạy sample_video.py là script chính để tạo video:
“`bash
python3 sample_video.py \
–video-size 720 1280 \
–video-length 129 \
–infer-steps 50 \
–prompt “A cat walks on the grass, realistic style.” \
–flow-reverse \
–use-cpu-offload \
–save-path ./results
“`
### 2. Web Demo giao diện Gradio
Mô hình cung cấp sẵn một server chạy Gradio để tương tác qua giao diện web:
“`bash
python3 gradio_server.py –flow-reverse
“`
Có thể cấu hình `SERVER_NAME` và `SERVER_PORT` thủ công nếu cần.
### 3. Suy luận song song trên nhiều GPU (x.DiT)
Hỗ trợ suy luận song song qua xDiT (Unified Sequence Parallelism – USP), giúp tăng tốc đáng kể khi có nhiều GPU. Ví dụ chạy trên 8 GPU:
“`bash
torchrun –nproc_per_node=8 sample_video.py \
–video-size 1280 720 \
–video-length 129 \
–infer-steps 50 \
–prompt “A cat walks on the grass, realistic style.” \
–flow-reverse \
–seed 42 \
–ulysses-degree 8 \
–ring-degree 1 \
–save-path ./results
“`
**Hiệu năng suy luận song song** (1280×720, 129 frames, 50 steps):
| 1 GPU | 2 GPU | 4 GPU | 8 GPU |
|—|—|—|—|
| 1904.08s | 934.09s (2.04×) | 514.08s (3.70×) | 337.58s (5.64×) |
### 4. Suy luận FP8 – Tiết kiệm VRAM
HunyuanVideo cung cấp trọng số lượng hóa **FP8** giúp tiết kiệm khoảng **10GB VRAM**. Trọng số FP8 và FP8 scale có thể tải từ HuggingFace:
“`bash
python3 sample_video.py \
–dit-weight ${DIT_CKPT_PATH} \
–video-size 1280 720 \
–video-length 129 \
–infer-steps 50 \
–prompt “A cat walks on the grass, realistic style.” \
–seed 42 \
–embedded-cfg-scale 6.0 \
–flow-shift 7.0 \
–flow-reverse \
–use-cpu-offload \
–use-fp8 \
–save-path ./results
“`
### 5. Tích hợp Diffusers
HunyuanVideo đã được tích hợp chính thức vào thư viện **Diffusers** của HuggingFace, cho phép sử dụng qua pipeline Diffusers API.
### 6. Image-to-Video (HunyuanVideo-I2V)
Một mô hình riêng biệt HunyuanVideo-I2V cho phép tạo video từ ảnh gốc, đã phát hành inference code và checkpoints.
### 7. Prompt Rewrite – Viết lại prompt
Fine-tune từ Hunyuan-Large để tự động chuyển đổi prompt của người dùng thành prompt tối ưu hơn cho model. Có hai chế độ:
– **Normal mode**: Nâng cao khả năng hiểu ý đồ người dùng.
– **Master mode**: Tăng cường mô tả bố cục, ánh sáng, chuyển máy quay – tạo video chất lượng hình ảnh cao hơn (có thể mất một số chi tiết ngữ nghĩa).
### 8. Docker image sẵn sàng
HunyuanVideo cung cấp Docker image cho cả CUDA 12.4 và CUDA 11.8:
“`bash
docker pull hunyuanvideo/hunyuanvideo:cuda_12
docker run -itd –gpus all –init –net=host –uts=host –ipc=host \
–name hunyuanvideo hunyuanvideo/hunyuanvideo:cuda_12
“`
### 9. ComfyUI hỗ trợ
Được tích hợp trong ComfyUI chính thức và thông qua ComfyUI-HunyuanVideoWrapper (hỗ trợ FP8 inference, V2V, IP2V).
### 10. Penguin Video Benchmark
Công cụ benchmark đánh giá hiệu năng video generation, được phát hành kèm theo repo.
—
## Kiến trúc tổng thể
Mô hình hoạt động trên không gian latent được nén không-thời gian qua **Causal 3D VAE**. Prompt văn bản được mã hóa bằng Large Language Model, sử dụng làm điều kiện. Từ nhiễu Gaussian và điều kiện, mô hình tạo ra latent đầu ra, giải mã thành ảnh hoặc video.
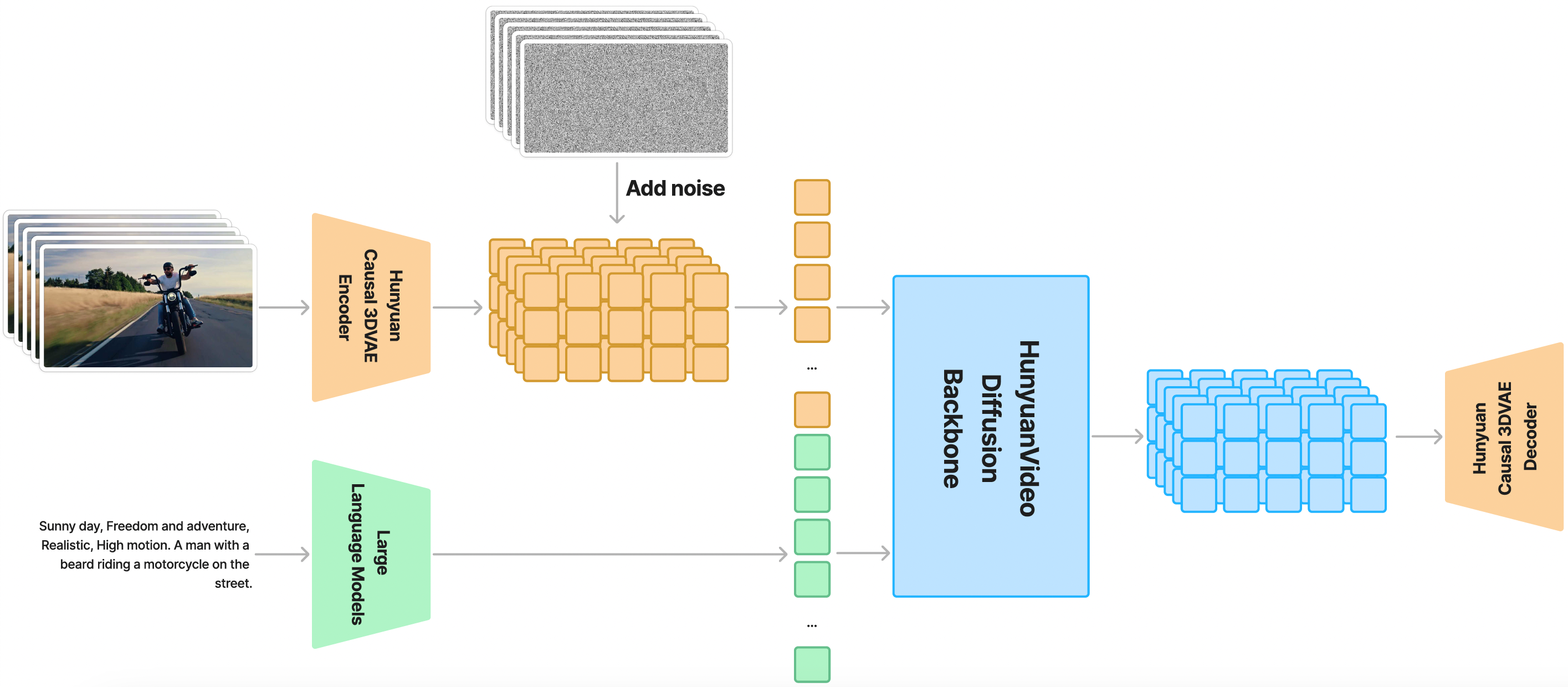
### Kiến trúc backbone – Dual-stream to Single-stream
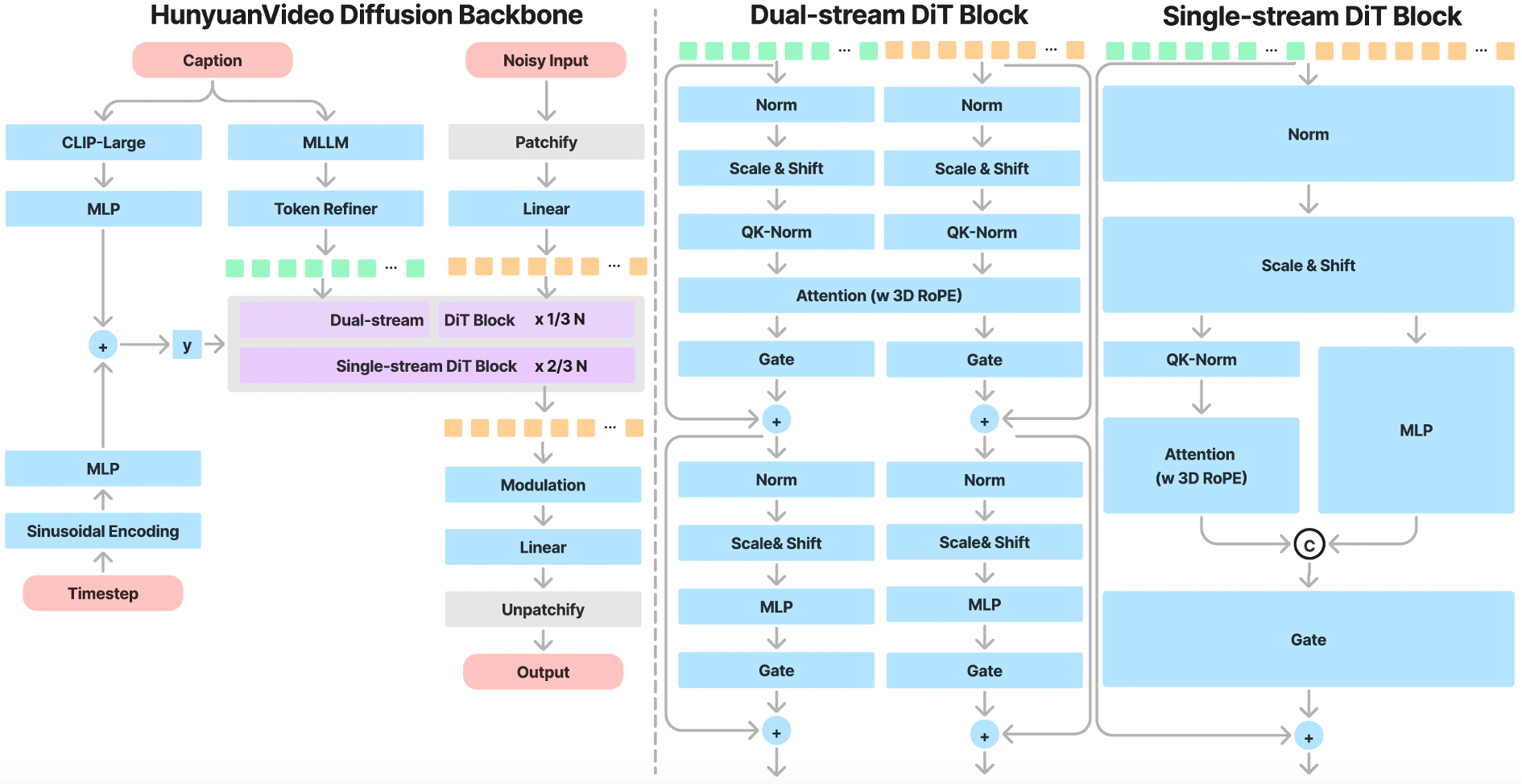
Trong giai đoạn **dual-stream**, token video và text được xử lý độc lập qua nhiều Transformer block. Trong giai đoạn **single-stream**, chúng được nối lại và đưa vào các Transformer block tiếp theo để kết hợp thông tin đa modal.
### Mã hóa văn bản – MLLM Text Encoder
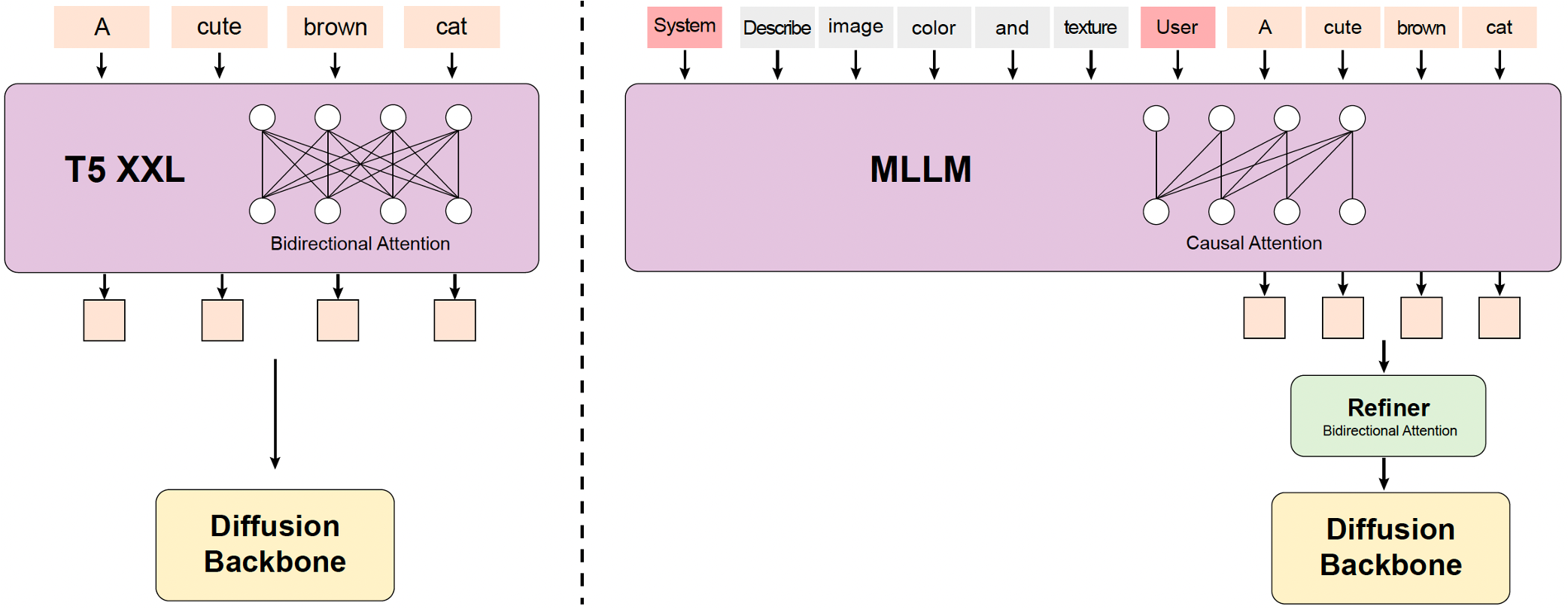
Sử dụng **Multimodal Large Language Model (MLLM)** với cấu trúc Decoder-Only thay vì CLIP hay T5 truyền thống, kết hợp với bidirectional token refiner để tăng cường đặc trưng văn bản.
### 3D VAE với CausalConv3D

Nén video/image theo tỷ lệ **4× (chiều dài video) × 8× (không gian) × 16× (kênh)** → giảm đáng kể số lượng token cho Diffusion Transformer.
—
## Yêu cầu hệ thống
| Cấu hình | VRAM tối thiểu |
|—|—|
| 720px×1280px×129f | **60GB** |
| 544px×960px×129f | **45GB** |
| Khuyến nghị | **80GB GPU** (ví dụ: A100, H100) |
– OS: Linux
– Python 3.10.9, PyTorch 2.6.0, CUDA 11.8 hoặc 12.4
– Flash Attention v2.6.3, xfuser 0.4.0
—
## Các dự án liên quan từ Tencent
| Dự án | Mô tả |
|—|—|
| **HunyuanVideo-1.5** | Phiên bản mới hiệu suất cao hơn (Nov 2025) |
| **HunyuanVideo-Avatar** | Tạo hoạt ảnh nhân vật từ âm thanh |
| **HunyuanCustom** | Tạo video tùy chỉnh đa phương thức |
| **HunyuanVideo-I2V** | Chuyển ảnh thành video |
—
## So sánh hiệu năng
| Model | Open Source | Text Alignment | Motion Quality | Visual Quality | Overall | Rank |
|—|—|—|—|—|—|—|
| **HunyuanVideo** | ✔ | 61.8% | **66.5%** | 95.7% | **41.3%** | **1** |
| CNTopA (API) | ✘ | 62.6% | 61.7% | 95.6% | 37.7% | 2 |
| CNTopB (Web) | ✘ | 60.1% | 62.9% | 97.7% | 37.5% | 3 |
| GEN-3 alpha (Web) | ✘ | 47.7% | 54.7% | 97.5% | 27.4% | 4 |
| Luma 1.6 (API) | ✘ | 57.6% | 44.2% | 94.1% | 24.8% | 5 |
Đánh giá bởi hơn **60 chuyên gia** trên **1.533 prompt**, theo 3 tiêu chí: Text Alignment, Motion Quality, Visual Quality.
—
Source link: [HunyuanVideo – GitHub](https://github.com/Tencent-Hunyuan/HunyuanVideo)